Build a trusted data foundation in Databricks
Eliminate data silos
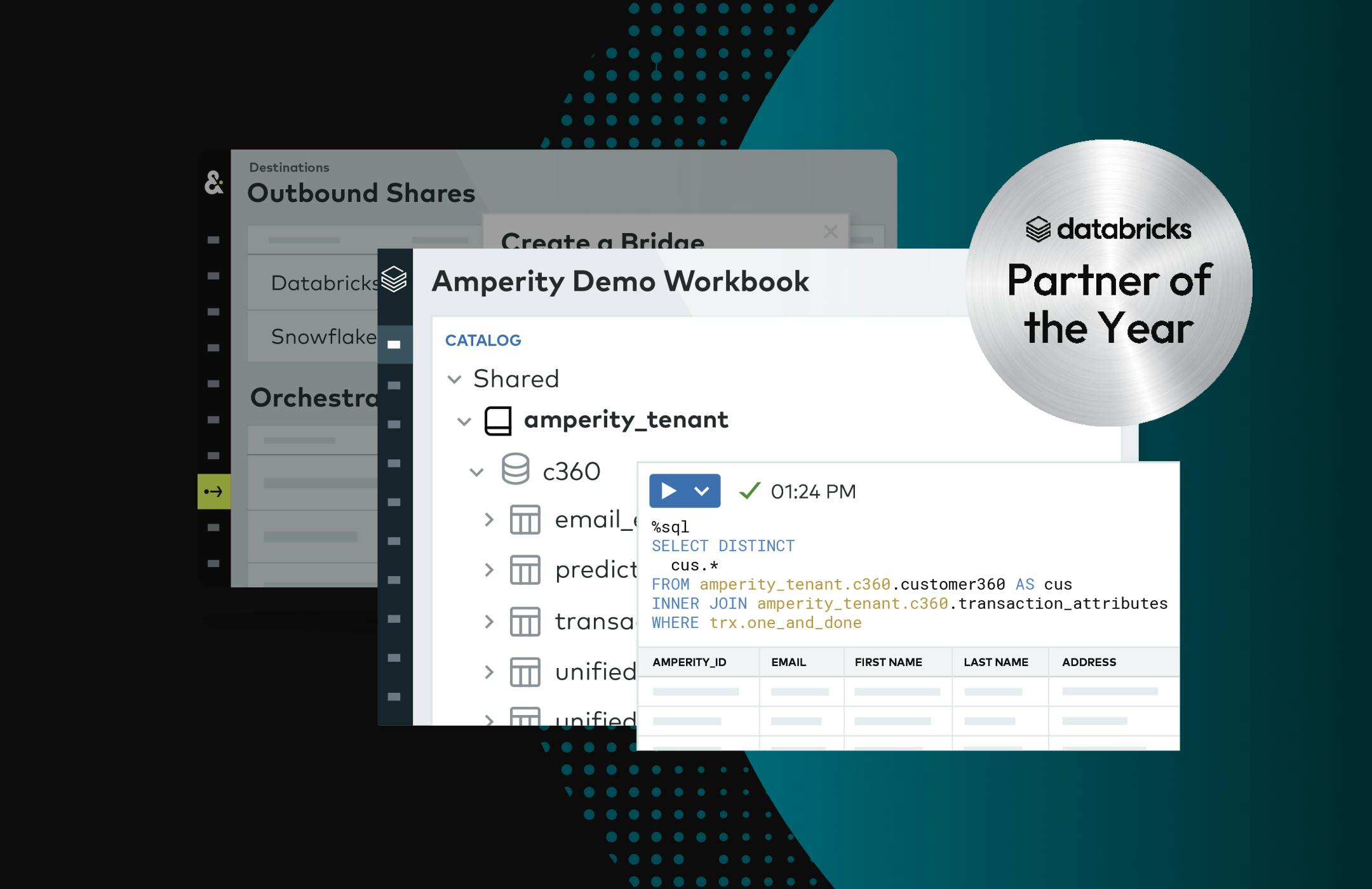
Set up a bi-directional data share in minutes with Amperity Bridge. Easily access shared data anywhere with Databricks’ Unity Catalog.
Enrich lakehouse data
Don’t waste time building profiles with cascading business logic. Automate identity resolution and unify profile data with an AI-powered toolkit.
Send data anywhere
Activate data stored in Databricks by using Audience Hub to send enriched customer data to 200+ destinations.
Amperity Bridge
Amperity Bridge enables zero-copy data sharing to and from a data lakehouse. It uses each lakehouse’s open, industry-standard data formats so data is available across the tech stack through a shared catalog.
Fast set up
Connect Amperity to Databricks in minutes using sharing keys instead of integrations. Accelerate time-to-value by gaining access to view and shape data quickly.
Zero copy
Control access to shared tables without replicating data across platforms. Save time building pipelines and save money by only storing data in a single place.
Scalable processing
Enrich massive volumes of data quickly since data is not moved or transformed from where it resides. Model customer data directly in Databricks or Amperity.
Live data
View customer data at rest in each environment through a shared catalog. Start exploring and querying data without waiting for refreshes or updates.
"A lot of organizations find that when building the 360 view, connecting customers across data sources is where it becomes very difficult. Amperity has built a solution that is capable of managing this space."
Get a clearer picture of your customer data
The Amperity Data Diagnostic is a fast, low-lift way to evaluate how ready your customer data is to drive business outcomes. Using your actual customer data, we’ll highlight strengths, uncover hidden issues, and show you how to unlock more value with accurate identity resolution.

How data and AI transform customer loyalty with Databricks, Amadeus, Slalom, and Amperity
Loyalty programs are no longer just about points—they're about personalization. Join industry leaders from Databricks, Slalom and Amadeus as they reveal how data and AI are transforming customer loyalty in travel.

Amperity is Databricks' Communications, Media, and Entertainment Partner of the Year
Amperity was awarded Databricks’ Communications, Media, and Entertainment Partner of the Year for our work delivering exceptional solutions tailored to our key clientele with marketing and consumer engagement use cases. We were also named Databricks' Built-on Partner of the Year in 2023.

