This is a summary of a research paper; if you’re a data scientist, you’re in for a treat, and if you are less technically-inclined then get ready to learn all sorts of new things.
Entity matching – the task of clustering duplicated database records to underlying entities – has become an increasingly critical component in modern data integration management. As businesses seek to better use a growing amount of data, the importance of entity matching, and data integration systems more broadly, has grown substantially to become a mission-critical component. In particular, such systems have become a key part of how direct-to-consumer brands use their customer data to drive decisions in products, customer service, and marketing.
Below I outline the three commonly overlooked challenges in entity matching. A more detailed and in-depth treatment can be found in our research paper titled “Entity Matching in the Wild: A Consistent and Versatile Framework to Unify Data in Industrial Applications” that will soon be published at SIGMOD '20: Proceedings of the 2020 International Conference on Management of Data.
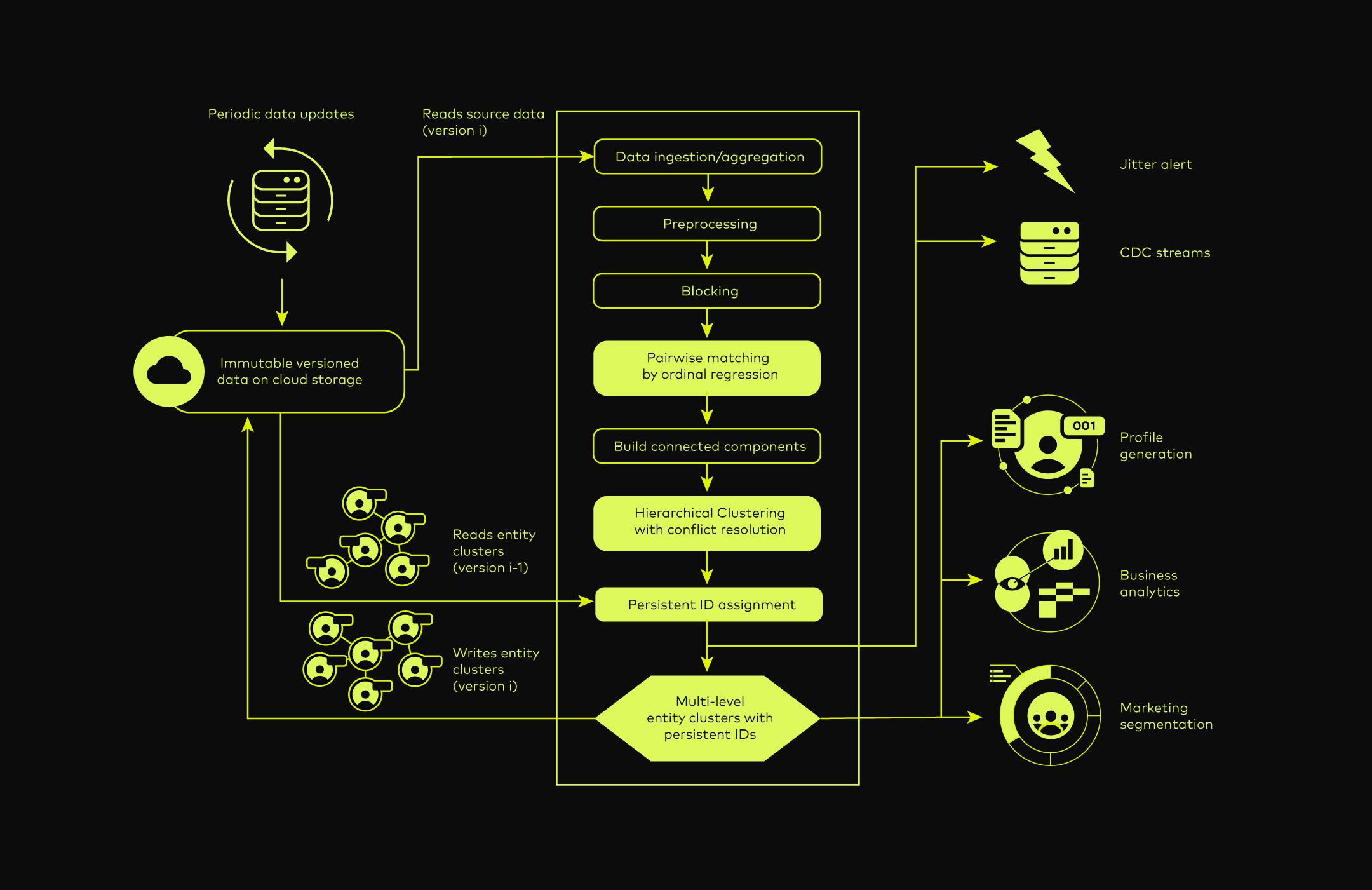
Entity matching is a straightforward problem to define: given a large collection of records, group them so that the records in each cluster all refer to the same underlying entity. While this definition captures the core of the problem, deploying systems that use entity matching typically face challenges not encapsulated by this definition. At Amperity, we have developed Fusion, a unique entity matching system that overcomes three commonly overlooked challenges in entity matching systems.
Challenge #1: Generating entity matching results at multiple confidence levels
Most entity matching systems provide a single version of entity matching results, assuming the canonical version of true entities does exist and is reachable. However, in real-world applications, there is a large degree of uncertainty about whether records refer to the same entity, and this uncertainty affects how we use the entity matching output for different downstream applications. Fusion supports entity matching at multiple confidence levels to enable applications with varying precision/recall trade-off needs.
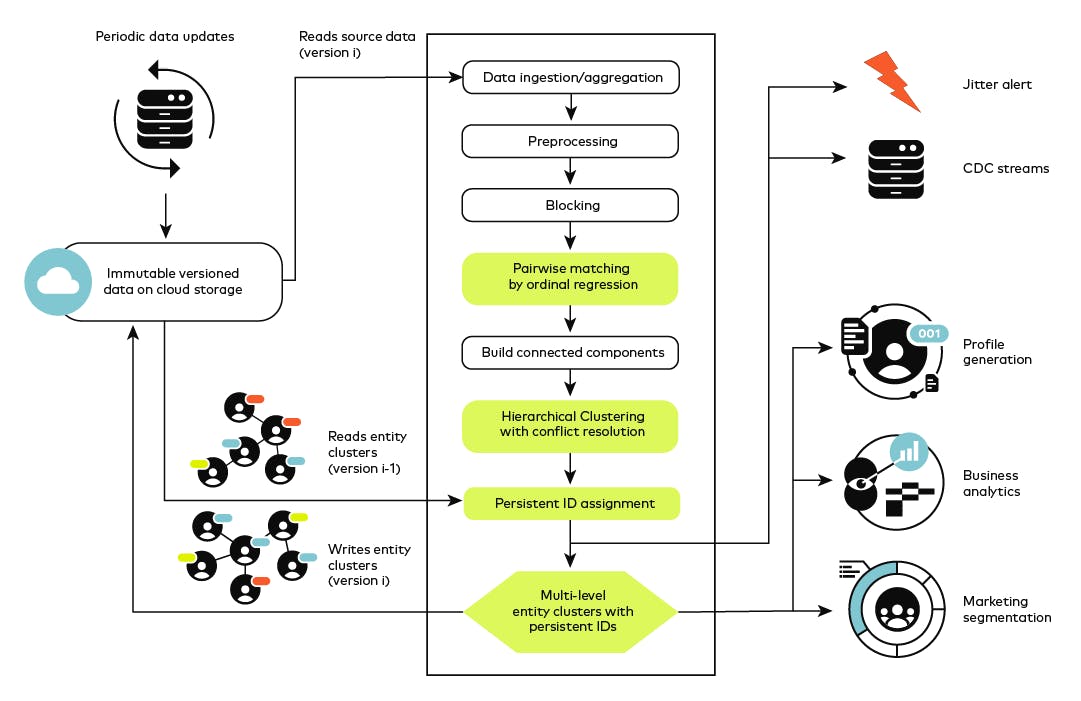
For direct customer interaction, such as an email survey asking "How was your purchase last week?", a business typically requires high confidence in the matching results since being wrong will create a negative customer experience. In contrast, if the email content is less specific, the cost of a precision error can be lower and we may be willing to trade lower precision for increased recall. Given the scale of the data (in the billions of records at Amperity), it is expensive to run entity matching end-to-end multiple times for each application and its preferred precision/recall trade-off. To the best of my knowledge, we are the first company to use ordinal regression instead of binary classification to model the entity matching problem. This permits us to produce multiple clusters at different match levels while paying the full cost of entity matching only once. The match levels we commonly used are hard-conflict, non-conflict, weak-match, moderate-match, strong-match, ordered by confidence level from low to high.The different outcomes based on three confidence levels are illustrated in the figure below.
Challenge #2: Resolving conflicts in entity clusters
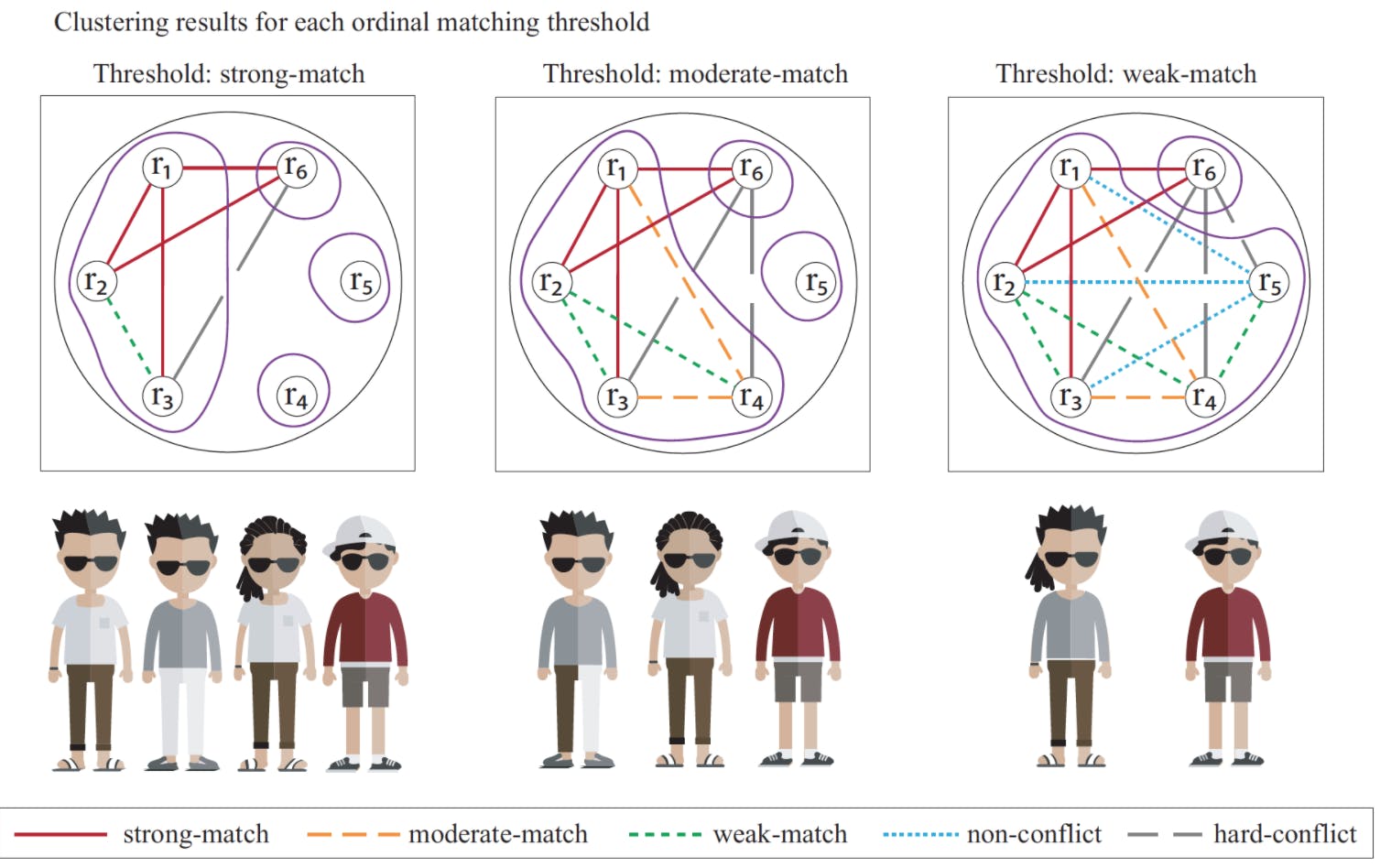
The goal of entity matching systems is not just to detect pairs of records associated with the same entity, but rather to produce coherent clusters. A common approach in entity matching systems is to create entity clusters by forming connected components (e.g, transitive closure) over detected pairs of similar records. The transitive closure can lead to the formation of long chains of records, where individual pairs are identified as matches, but multiple records in the chain can be quite different from each other; see the figure below for an illustrated example.
Most existing approaches resolve this issue by performing some form of graph pruning over the transitive closure to split the clusters with negative edges (i.e., record-pairs that are classified below the match-threshold). Crucially, many of these approaches assume that this problem occurs exclusively because of conflicting information, whereas in many practical settings, they arise due to information systematically missing from a source of data. The Fusion system deploys a novel patent-pending clustering algorithm that only eliminates the record-pairs with real conflicts while letting other unmatched record-pairs remain transitively connected.
Challenge #3: Maintaining stable entity identifiers over time
Entity matching never exists in isolation, and most of the time it needs to be integrated and synchronized with downstream data management systems. Typically these systems will accept new information on a daily or real-time basis which will, in turn, trigger the re-clustering or updating of existing entity clusters. Downstream applications of entity resolution will typically need ways to "refer" to a canonical entity even though our beliefs about which records constitute an entity may change over time. This creates several problems which must be addressed to successfully utilize entity matching in a practical setting:
How to create a unique identifier to track each real-world entity even if the cluster of records associated with the entity changes over time?
How to identify if an entity (not a record) is added to or deleted from the system?
How to provide a single metric to evaluate the disparity between two clustering
Unlike the traditional entity matching systems, Fusion has an additional step of assigning each entity with a persistent identifier. The entity identifier is persistent in the sense that it remains in the system as long as the entity still exists, even if the actual cluster composition changes over time. A new identifier is created when records that represent a new entity appear, and an identifier is removed when all the records associated with the entity are deleted completely. This procedure not only enables us to track each real-world entity with ever-evolving information but also helps businesses stay compliant with data protection regulations such as GDPR and CCPA when handling data erasure requests.
The work discussed above is summarized in our research paper titled “Entity Matching in the Wild: A Consistent and Versatile Framework to Unify Data in Industrial Applications” that will be soon published at SIGMOD '20: Proceedings of the 2020 International Conference on Management of Data.