
This one goes out to the data engineers.
The modern tech landscape has data engineers living in a perpetual tedium loop.
Every day, teams get to work and face a queue of requests to manage data. That’s part of the job of course! Nothing wrong with that.
The problem is the lack of variety. Variety is the spice of life and data engineers have been stuck with a menu of plain oatmeal for far too long.
The main data models
Data teams are constantly working on jobs to format and model data.
The problem is that there are a fairly minimal number of data models.
Model | Description |
Identity | Profiles, devices, customer records, personas, loyalty, etc. |
Transactions | Summary level data of an entire transaction |
Itemized Transactions | Item level data for a transaction |
Products | Catalog of products and their descriptive fields |
Campaigns | Marketing campaigns, often by channel |
Campaign responses | Engagement, sends, clicks, opens, etc. by channel |
Preferences | Contact preferences, opt status by channel, etc. |
Households | Typically a grouping of individual identity by some sort of logic around living together or sharing an account |
Accounts | Account level business models. This can be business accounts but also things like a subscription or user account. |
Events & Interactions | I’m using this generally for the sake of brevity, but some sort of data model logging a specific interaction. A visit, click, loyalty points, etc. Examples: web events, channel engagement events, loyalty events, reservations |
Surveys | Survey data and survey response data |
Support | Support tickets, compliance requests, etc. |
That’s 12. It’s not an exhaustive list of course but having worked with so many enterprise companies over time it’s certainly covering the vast majority of data models I have encountered that drive and measure the core aspects of a business.
The tedium loop
Every day is exactly the same for teams developing and managing data and translating the ~12 data models between systems makes up a simply unacceptable amount of our lives.
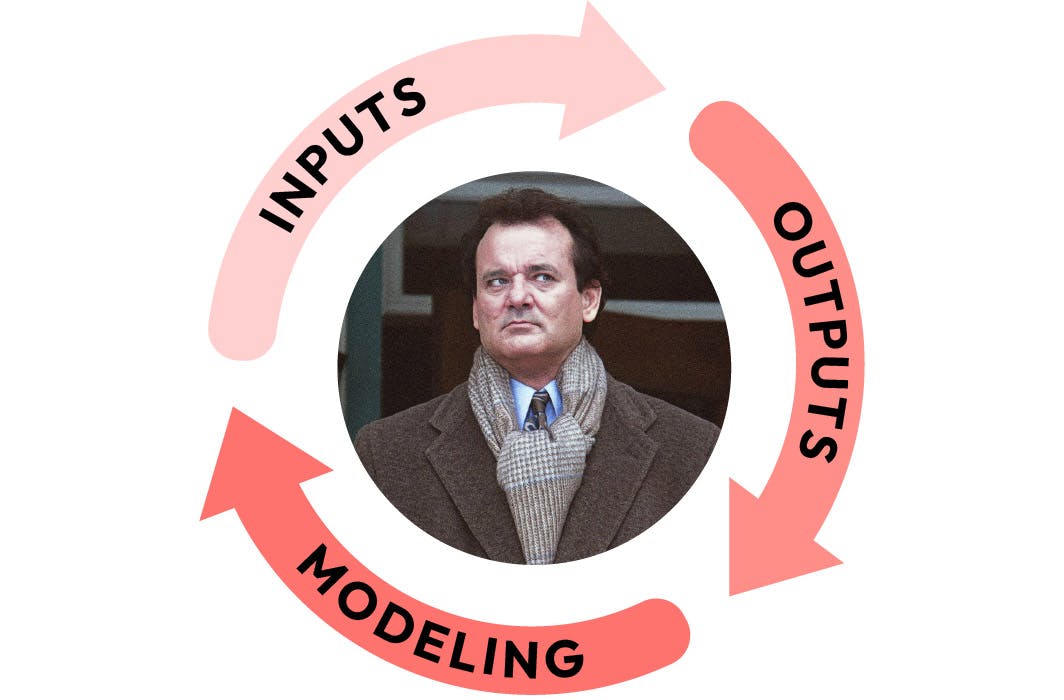
Every task comes down to the same three tasks:
Understand the inputs. This means researching the source you’re pulling from. How is it stored? What are its rules?
Understand the outputs. This means researching the destination you’re sending data to. What interface do you use? What are its rules? How does it affect the application.
Write or update the data jobs. The vast majority of the time this means translating between the same handful of data models.
A basic example
The ACME Corporation uses Shopify data and wants to send email marketing to them in Salesforce Marketing Cloud.
Shopify stores data in this format. (Credit to Fivetran for the ERD.)
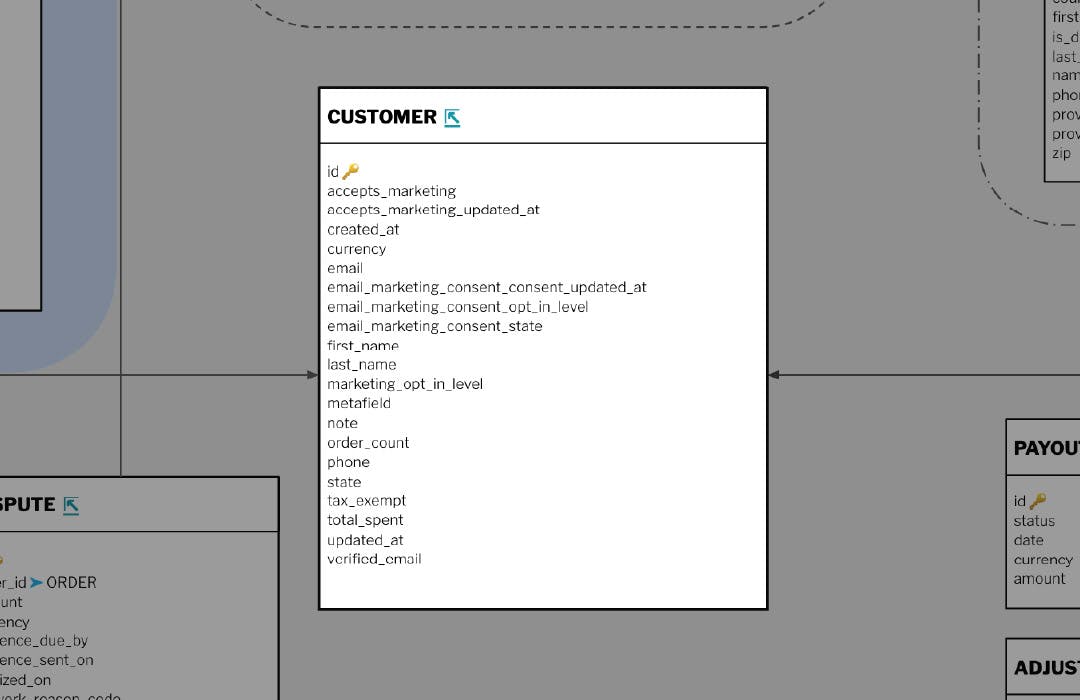
There is a unique ID field, names and emails.
Salesforce Marketing Cloud calls them “Contacts” and needs the data mapped to specific fields via these APIs:
{
"Salutation": "Mr.",
"FirstName": "Frodo",
"LastName": "Baggins",
"Email": "frodo@bagend.com",
"MobilePhone": "+448575550142"
}
So the data engineer writes an ETL (or equivalent) that converts the data from the Shopify system format to the SFMC format and automates it to feed the data from A to B.
Simple enough?
Sure, but it happens all the time and constantly.
An expanded example
In the real world, enterprise companies don’t only have one source of data, and commonly have invested heavily into some sort of unified data model.
For profile data this results in something like the following:
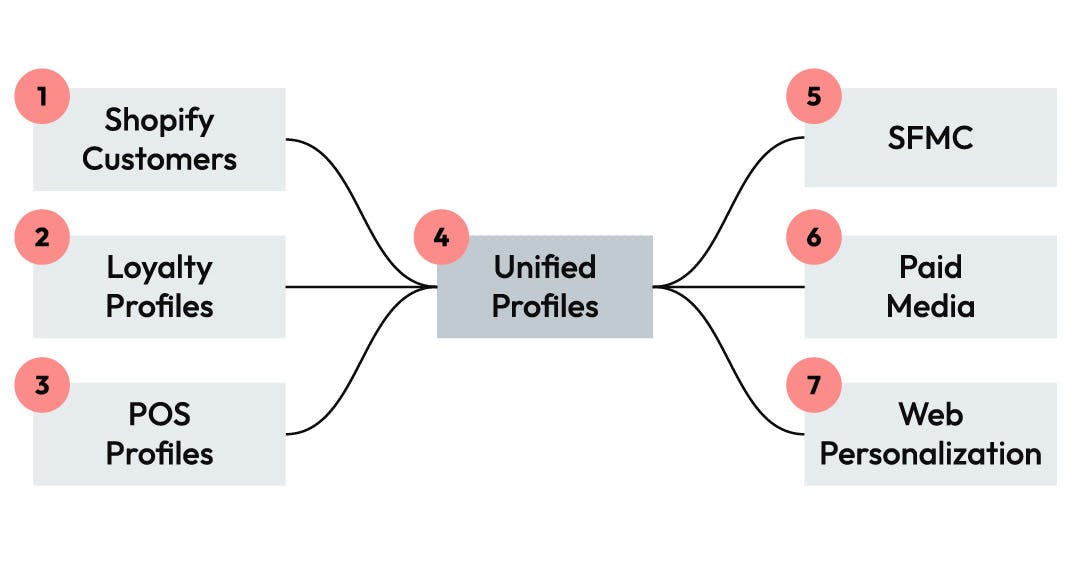
Each source system has to be extracted and formatted into a unified model.
The unified model has to have ID resolution or some sort of clean-up and deduping concept.
Each destination needs the unified model translated into their schema and interface.
At a minimum we are talking about 7 different jobs for a data engineering team to develop.
In reality this is oversimplified because each system probably needs some sort of raw data extraction job, data cleaning, special rules, etc.
Let’s say it takes an average of 10 hours of work to write each job. That’s 70 hours of work to do something that has been done millions of times all over the world. The same way everyone does it. Over and over and over.
And so the loop continues.
The cost of the loop
The frustrating thing about this is that we have all gotten so damned used to this loop that we sometimes don’t even realize that we are in it. It’s just part of the job.
The problem is that all of this tedium has a massive cost both to companies and to our sanity.
Cost 1: the money of it all
Let’s get the boring one out of the way. Time is money. Data engineers aren’t cheap. Compute and storage aren’t cheap. The more jobs a data team has to build and maintain, the more time and COGS it takes. The time and effort is a sneaky, hidden cost that gets overlooked often because of how numb to the loop we have become.
Cost 2: opportunity cost
This is more important to a business. Every hour a data engineer spends formatting another of the same data models between A and B is an hour they could be spending on something that drives actual revenue.
Some examples of better ways to use time are:
Predictive models to better recommend products, identify churn risks, etc.
AI and LLM development to drive more innovative experiences and efficiency gains
Refined financial models to better understand customer spend
These have a higher impact for a business. They will directly drive better engagement and spend.
They are also just far more interesting to work on.
Cost 3: sanity
Let’s be honest, nobody wants to work on basic data translation jobs. When you first start your career it is interesting but after a few years it’s just tedious “translate A to B” work over and over and over.
You aren’t learning new technologies. You aren’t writing and refining interesting algorithms. You aren’t even necessarily growing your own skills. It’s necessary work of course but over time it’s brain poison.
Let’s talk about how we can break the loop.
Breaking the loop
The good news is that it doesn’t have to be this way.
There are only a handful of data models. Software should be able to handle that.
Here are a couple of ways to drastically reduce the amount of time spent in the loop.
Native integrations
Many modern SAAS tools have tried to eliminate the loop by providing some sort of OOTB connectivity between modern apps.
If we revise the earlier example of integrating Shopify with SFMC and choose something more modern for email activation like Braze, Braze and Shopify have partnered and there is a native way to connect to two. This makes the Shopify contacts and various other valuable bits of information stream into Braze without needing to build any sort of translation layer.
This is neat and very valuable for smaller companies. The problem is that as a company grows there are going to be plenty of systems without that integration and if you end up with 2-3 jobs updating the same APIs from a silo it can end up a bit of a rats nest to administrate. That said, it’s certainly low friction!
Semantic layers
Since there are only a handful of common data models, a newer innovation is using a semantic layer. This eliminates many of the most tedious steps involved in translating data from A to B by letting data engineers simply tag fields on data and letting software do a bunch of the standardization work.
Amperity has a constantly growing library of these for the common data models.
This makes it possible to simply tag a field and let the software do more of the work.
For example, most profile models will have first name, last name, email, etc.
Instead of having to know that in Shopify it is “first_name” and in SFMC it is “FirstName” and codify that, you just tag the data and Amperity handles the rest.
This is especially powerful and eliminates a mountain of tedium.
Instead of having to get deep into the research of the source system, you can simply tag the data and let an algorithm spit out standardized tables.
Connector frameworks (SaaS ETL and reverse ETL)
A key element of building a data architecture is getting data from the sources and to the destinations. In older systems that means learning the interfaces for each system and writing actual code to pull or push the data.
SAAS ETL tools offer libraries of connectors to pull data from applications and put them into storage. Reverse ETL tools do the opposite, pull data from storage and put it into applications.
These reduce a lot of tedium. They keep the connectors up to date for you and remove a lot of the custom development. Unfortunately they don’t translate between each other. SAAS ETL just puts raw data into storage, Reverse ETL just pulls it out of storage. You’re still stuck in the loop, you just can only do it in your data warehouse without worrying about the interface so much.
Data unit testing
One way to save time is to create tests at key steps in the data model that validate assumptions about that model.
If we use one of our above examples, we can put tests on our unified data model which can run as you update upstream processes. This means you can make changes and make more assumptions and the tests can catch problems if something breaks assumptions about the target data modeling.
Amperity’s combo move
Our goal at Amperity has always been to figure out how to break this loop.
This is a problem every single company is solving in one way or another. There are only so many data models. There should be a way to use software to handle this.
The key is combining all of the techniques described above in a single offering.
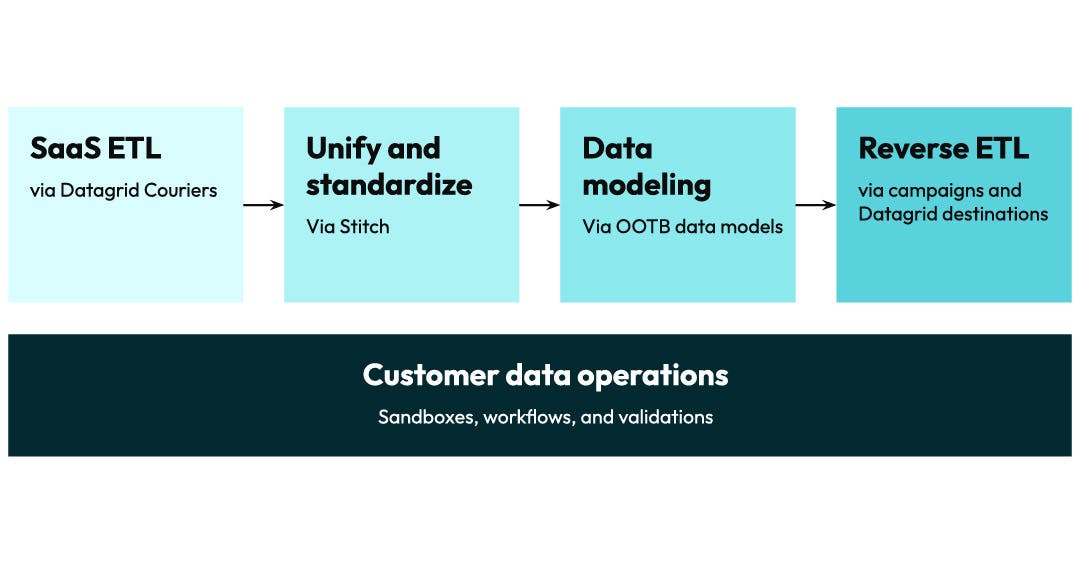
By offering a carefully tuned and selected combination of all of the tools needed for the full data pipeline, Amperity can reduce the level of effort needed to set up a CDP by 70% or more.
By offering a dedicated set of features for change management and monitoring, we can reduce the effort to make changes and support a live system by 86% or more.
But…how?
That sounds great but also sounds like magic. The good news is that it is sort of both.
If we look at the full pipeline, setting up Amperity works like this:
Get the data: We have a huge library of connectors and native connectivity with data warehouses to get all of the raw data connected.
Tag the data: Instead of requiring any specific formats, we have a library of semantic tags for the majority of the common data models listed earlier.
Run Stitch: Stitch uses the tags and creates a standardized set of tables for each domain. It then uses up to 45 different ML models to generate a unified ID called an Amperity ID, which it propagates to all of those tables based on the configured tags.
Layer on data models: Since Amperity does the work to generate the standardized data, the platform now has the knowledge to easily layer on a library of OOTB data models.
Validate the results: Since Amperity provides the models, we also can provide a bunch of pre-written unit tests and validations to identify any issues that need to be addressed. We also have a proven library of Stitch QA queries to identify common issues.
Tune and tailor: Address any issues found in the validation reports, adjust Stitch settings and alter the models to reflect use cases your business cares about.
Democratize the data: Give marketers access to AmpIQ to self-serve their campaigns. Set up Destinations or share the data directly into your data warehouse. Amperity handles all of the interface details and keeps the connectors up to date.
That’s pretty much it. If it sounds like a lot, remember I’m talking about starting from scratch.
For an initial configuration, I can set up all of those steps in under an hour. The majority of the time is spent on validating and customization.
Living with Amperity
I find that most applications in our space really only focus on telling the story of the initial setup. The reality is that the majority of the time spent in the loop comes from living with the resulting architecture.
Making changes, updating things, adding fields, swapping datasets, etc.
This is an area where Amperity saves even MORE time.
Sandboxes - Amperity has patented systems to easily generate an entire dev environment to make changes. All it takes is a click and you can start making changes in a branch separate from your production environment. Sandboxes include validations to identify where a change make break something and makes it safe and easy to make changes.
Workflows - A key benefit of using a Lakehouse CDP like Amperity is that the entire data pipeline happens in one platform. Automating and monitoring the data flows happens end-to-end and notifies teams if anything unexpected happens. This not only covers basic errors, but monitors things like the ID graph and notifies if there are unexpected shifts in identity.
Validations - The OOTB validations run every time the data is refreshed, notifying you if something changed unexpectedly. We also have query alerts that make it easy to write your own unit tests for specific cases you want to monitor.
All of these things make it easy to make changes. Want to swap a dataset? Make a sandbox, swap it, run your validations and compare it to prod, push to prod. Broke something? Easily rollback to before you pushed the change.
Wrap up
It’s time to break the loop. Data engineers need to let the software do the tedious work for them. Companies that do can spend their time building the models and tools that are not only far more interesting and stimulating to work on, but that drive more revenue.
To learn how Amperity can help your brand improve its customer data quality while saving your engineers from unending integration headaches, check out our Lakehouse CDC video.