
Recently, Google published its strategy for managing the security challenges of its AI agents. Google argues that developers need to prioritize protecting sensitive data and applications from attacks by bad actors and wayward code. Today, I wanted to take a quick look and provide some perspective on Amperity’s response to these same concerns.
Agentic concerns
The vision of an AI agent is for software to handle multistep workflows intelligently and in ways where it can adapt to ambiguity or change with as little intervention as possible. Google’s paper highlights two primary risk areas for these agents:
Rogue actions - protecting against an agent doing unintended or dangerous things due either to hallucination from the LLM or from a bad actor engaging in things like prompt injection.
Sensitive data disclosure - protecting against an agent exposing sensitive information due to unexpected behavior or from a bad actor.
I agree these are the key risks, but I also think that a well-designed agent has many ways to mitigate those risks. I also think it’s actually probably harder to create a truly dangerous agent (currently) than it is to make a safe one. (The primary caveat would be low-skill engineers, who don’t know how to think about security, vibe coding an agent - but in a market as explosive as the AI market, I struggle to imagine those offerings receiving mass adoption.)
Google also describes three main mitigation strategies that emphasize my point:
Mandate humans oversee any higher-risk actions taken by agents.
Use a clear permission structure to limit agent powers.
Maintain clear observability of agent actions to track what they did.
These are great principles, and I want to show how our approach embraced these concepts (before this paper was published) when developing Chuck Data.
Restricting access by design
At launch, these are the primary tools that Chuck had at its disposal to help implement customer data engineering use cases in Databricks:
Tool Category | Capabilities | Risk Profile |
Unity Catalog features | Read, describe, and tag Unity Catalog entries in a Databricks account | Low |
SQL features | Run SQL queries, the majority of which are pre-defined READ queries | Low |
PII profiling features | Evaluate tables to identify fields containing sensitive data and determine what kind of information they hold | Medium |
Create notebooks | Generate the Stitch notebook | Low |
Run Stitch | Run Amperity ID Resolution in Databricks, creating new tables and potentially new schemas | High |
I’ve defined the risk profile for each tool category relative to Google’s two major risks. If we use the Unity Catalog features as an example, as of July 2025 Chuck is permissioned to use the following tools:
List catalogs
Describe catalog
List schemas
Describe schema
List tables
Describe tables
Currently, Chuck doesn’t have any tools that could delete or modify a Unity Catalog entry, meaning that Chuck’s primary risk would be exposing knowledge of the data structures in a Databricks account. However, we further mitigate against this exposure by limiting Chuck’s access through its API key, which is tied to a specific user. Finally, Chuck logs all of the tool calls made by the agent, which means we can track its every response and action to user prompts.
In this example, Chuck is adhering to all three principles outlined by Google.
Agent design choices
The key in designing secure agents comes from understanding the risk profile of each tool and making each tool react accordingly. If we compare the Unity Catalog tools to the Stitch run tools, there is a major difference: running Stitch creates new data and consumes much more resources. As a result, any time you run Stitch, the Chuck code prompts the user to confirm additional actions, keeping the human in the loop.
The important part is that LLMs aren’t actually magic and by themselves can’t actually DO much. The LLM takes in the user prompt as well as context provided by the application and provides a response. The agent application code uses that response to determine which tool calls to make, at which point the actual actions taken by tools are entirely normal code and deterministic. As a result, agent security should never be determined by the LLM.
A poorly designed agent would have the LLM deciding whether an action requires a human in the loop or whether they have access. That is not what LLMs are good at.
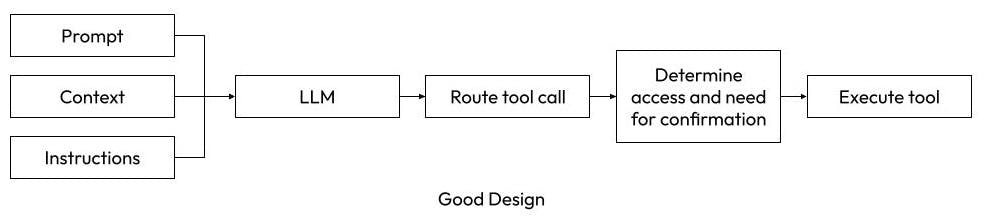
Good Design: The LLM takes input and is told to recommend the tool(s) to execute. The tool code validates the request and has hard-coded behavior to validate access or seek user confirmation.
Bad Design: The LLM takes input and is told not to recommend certain tool(s) based on user context. The logic to restrict behavior is embedded in model prompts rather than enforced through tool-level validation.
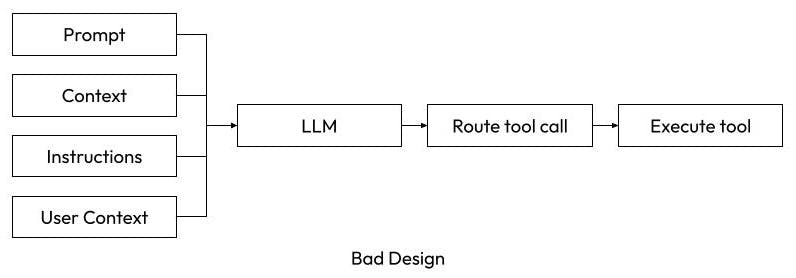
If the above two diagrams make you think, “why would anyone implement it as the second option?” then you are getting a sense for why I think it’s actually harder to make dangerous agents. In my opinion, the biggest problem with dangerous tool calls comes from the authentication the tool is using. Chuck is limited by a user’s API token, so it can only do things the user would be able to do and is fully restricted by a company’s existing governance. In some applications, the agent will have its own dedicated credentials and potentially have far more access than the user would have, at which point you have to make sure the tool code identifies risky actions and prompts a human for confirmation. Both methods can work as long as you follow the principles Google laid out.
Well-written tools are also an easy way to handle prompt injection. Chuck Data lets the user choose their LLM from their Databricks account. It’s entirely possible that a user could write a prompt that tells it to disregard all instructions, but at that point it would basically be as powerful as directly prompting a basic LLM endpoint within Databricks. The tools are the point where action actually happens. It’s on the developer to make sure that the tools react appropriately to risk and security - but that code has nothing to do with LLMs, so it’s no different from non-agentic software principles.
I’ve never seen a new technology create such fast evolution in the tech space as LLMs have. The opportunity is massive, but with great opportunity comes great risk. If you’re developing agents, it’s worth considering users prompting literally anything and making sure the tool code handles the risk mitigation. Just ask Google.
For more: Watch Amperity’s head of AI, Joyce Gordon, discuss secure agentic tooling at the Enterprise AI Agents Summit 2025.