
It’s hard to check industry news these days without seeing a cascade of announcements in the AI space: New LLMs, new startups, new funding rounds, and new agents—all with the compelling pitch to do more with less. To date, we’ve seen agents focused on customer service, personalization, and general-purpose software engineering.
However, there are also massive opportunities for agents to transform customer data engineering by eliminating repetitive and tedious effort. Today’s customer data management approach still relies heavily on implementing time-consuming and complex code. But we believe agentic applications can reshape data engineering from its slow and resource-intensive drudgery to an accelerated and greatly simplified process.
An example data engineering task
We’ll start by explaining a basic task that a data engineer might encounter on a regular basis:
Task: Format a list of customers to be uploaded into Braze.
Translating this request into a generic list of tasks might look something like this:
Identify the table(s) with customer data.
Understand the data output format (i.e., account for Braze's format requirements).
Evaluate the data and figure out where opt status for email is stored.
Write a SQL query that selects the desired customers and filters out people who do not have an email address or are opted-out of email communications.
Validate the results (i.e., make sure they conform to the Braze requirements and fix the SQL query until it is correct).
Output the data as a CSV and send it to the team or agency that will upload it to Braze.
The task is overall simple and a bit boring, but depending on human factors could take several hours to complete. Agentic tooling, however, could drastically simplify this work.
Applying agentic concepts to our task
Let’s assign each of these tasks to generic concepts of an agent and see what kind of application could be more effective for engineers and data scientists.
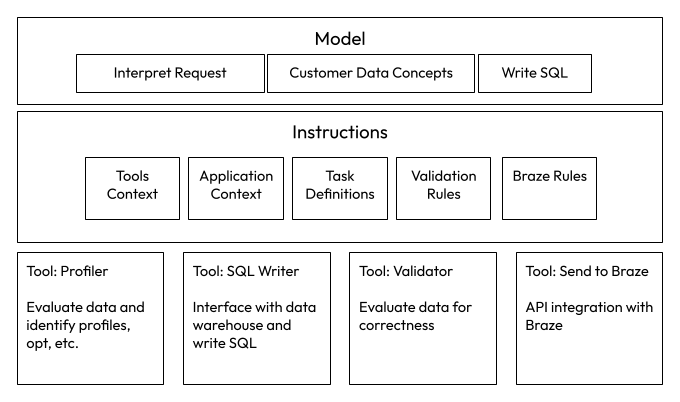
By applying agentic concepts to the problem, you get something like this:
Model: A large language model (LLM) brings generalized intelligence to the table. It can take the instructions and context, interpret the task, and break it into a combination of tools necessary to accomplish it. It can write SQL. It understands that data representing a person includes things like names, emails, etc.
Instructions: The instructions layer feeds context to the LLM about what tools it has, what tasks it is trying to accomplish, etc. It knows the rules for interacting with Braze, what validations to run, and it shepherds this information to/from the LLM.
Tools: The tools provide the specific interfaces to accomplish the tasks. A profiler can execute processes on the data to identify the tables that look like they have the customer data. The SQL writer can interact with the data warehouse via an SDK. The validator can apply a series of rules on the SQL output and make sure it is correct. The Braze tool can interact with Braze via their SDK and send the data directly.
The end result is an application that can interpret the task, understand the goal, and execute multiple steps, with the user only needing to interact if something goes wrong along the way. The application is embedded with expertise on the customer data domain, the applications it interacts with, and the tasks it needs to perform.
A future with fewer headaches
Historically, applications have features, and the user has to develop expertise to use them correctly. Agentic applications let software developers embed expertise directly into the application. Agentic applications can take care of the boring work and let data engineers focus on more interesting tasks:
Handling interfaces between applications: Applications have features, APIs, limitations, security rules, etc., that the agent can understand.
Relieving syntax fatigue: Different SQL dialects, different scripting languages, etc., are tedious to navigate; these rules and dialects can be handled by an agentic application.
Handling process and documentation: Finishing a task is satisfying. Writing code comments, git commit messages, updating documentation, updating JIRA tasks, etc., are tedious but necessary tasks that are more about organizational processes than execution. Agents can interpret code and update these things on your behalf.
Handling schema translation: A staggering amount of tedious data engineering tasks can be summarized as “convert data A into format B.” An agentic application can interpret data A and understand the rules of format B for you. It can even write tests for you!
In closing, it’s important to remember that it’s still early days for agents, and the most mature products can already take care of the low-hanging fruit. Put simply, an agent can perform useful tasks by interacting with different applications while using the power of LLMs to handle ambiguity that would otherwise rely on human intervention.